AI News Sites Blocked by Bot Detection as Publishers Deploy Anti-Scraping
Main Takeaway
Major AI news sites now blocking access with "Access denied" messages as publishers deploy bot detection to prevent unauthorized scraping.
Jump to Key PointsSummary
Why you're seeing access denied messages
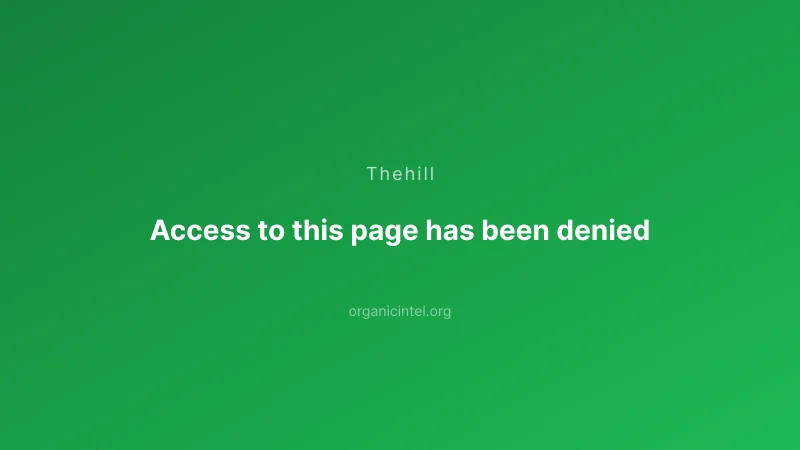
AI news publishers have quietly activated aggressive bot detection systems that block automated access to their content. The "Access to this page has been denied" messages appearing across major outlets like The Hill and DC News Now represent a broader shift in how news organizations protect their content from AI training and unauthorized aggregation.
These blocks typically trigger when systems detect non-human browsing patterns, automated scraping tools, or requests from data centers rather than residential IPs. The px-captcha systems mentioned in both blocked pages are part of PerimeterX's bot management platform, which news sites increasingly deploy to distinguish between legitimate readers and automated systems.
What this means for AI developers and researchers
The access restrictions create immediate friction for anyone building AI systems that rely on current news data. Researchers training language models, building news summarization tools, or conducting sentiment analysis now face systematic barriers that didn't exist six months ago.
Academic institutions and startups using web scraping for legitimate research purposes find themselves caught in the same net as malicious bots. The blanket approach treats all automated access as potentially harmful, forcing developers to either pay for API access (where available) or abandon news-based projects entirely.
This shift particularly impacts smaller AI companies and independent researchers who lack the resources to negotiate individual data licensing agreements with major publishers.
The hidden cost of content protection
Publishers implementing these blocks face a trade-off between protecting their intellectual property and maintaining reach. While blocking bots prevents unauthorized use of their content, it also limits distribution through legitimate AI-powered news aggregators and research tools.
The move reflects publishers' growing concern about AI companies using news content for model training without compensation. Recent lawsuits between news organizations and AI companies have accelerated adoption of technical countermeasures, even when those measures also block beneficial uses of news data.
This creates a fragmented information ecosystem where access depends more on technical sophistication and commercial relationships than public interest or research value.
How publishers are implementing these blocks
The blocking systems use sophisticated fingerprinting techniques that analyze browsing patterns, IP addresses, browser characteristics, and request timing. Unlike simple IP blacklists, modern bot detection creates behavioral profiles that can identify automated access even when it appears to come from residential connections.
Publishers typically deploy these systems during high-traffic periods or when they detect increased scraping activity. The Hill and DC News Now both activated their PerimeterX protections recently, suggesting coordinated response to perceived threats rather than individual publisher decisions.
These systems often provide tiered responses, showing captchas to suspected bots while allowing human users through, but appear to be configured for more aggressive blocking in these cases.
What happens next for content access
The current access restrictions likely represent an interim solution as publishers and AI companies negotiate licensing frameworks. Several major news organizations have already announced deals with AI companies for authorized content use, suggesting the blocking approach may be temporary.
Expect to see more sophisticated approaches emerge, including publisher APIs that provide controlled access to news content for AI applications. These would allow legitimate use while maintaining publisher control and enabling monetization of AI training data.
For now, developers and researchers should prepare for increased friction when accessing news content, consider official APIs where available, and factor licensing costs into project planning. The days of freely scraping news sites for AI training data appear to be ending.
Key Points
Major news sites now blocking automated access with bot detection systems
PerimeterX px-captcha platforms deployed to prevent AI training data scraping
Academic researchers and small AI companies face systematic barriers to news data
Publishers balancing content protection against legitimate research access
Shift toward controlled API access and licensing deals for AI companies
Questions Answered
News publishers have activated new bot detection systems that block automated access. Even if you've visited before, your current browsing pattern or IP address might be flagged as potentially automated.
Yes. Publishers are responding to AI companies scraping news content for model training by implementing technical barriers that block all automated access, including legitimate research use.
Options include using official publisher APIs where available, negotiating individual licensing agreements, or working with news data providers. Free web scraping is increasingly blocked.
Probably not. The current blocking appears to be an interim measure while publishers negotiate licensing frameworks with AI companies. Expect more sophisticated, controlled access methods to emerge.
Go deeper with Organic Intel
Simple AI systems for your life, work, and business. Each one includes copyable prompts, guides, and downloadable resources.
Explore Systems